
티스토리 뷰
[딥러닝 express]의 연습문제 11장 풀이입니다. (개인적인 풀이기에 오답이 있을 수 있습니다!)

Google의 colab에서 실행합니다.
Google Colaboratory
colab.research.google.com
9. FordA 데이터 세트를 이용하여 시계열 데이터를 분류해보자. FordA 데이터 세트에는 3601개의 훈련 샘플과 1320개의 테스트 샘플이 들어있다. 이들 시계열 데이터는 자동차 엔진 센서가 포착한 엔진 소음 측정 값이다. 이 작업의 목표는 엔진에 특정 문제가 있는 자동으로 감지하는 것이다. 이것은 이진 분류 작업으로 볼 수 있다. 시계열 데이터도 단순한 컨벌루션 신경망을 사용하여 분류할 수도 있다. https://keras.io./examples/timeseries/를 참조한다.
Keras documentation: Timeseries
keras.io.







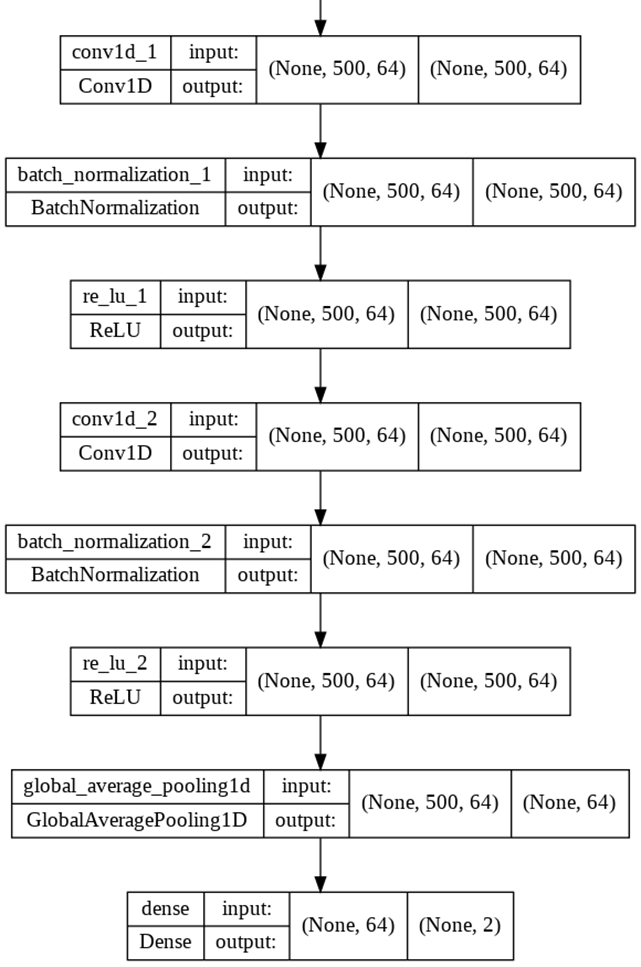





10. 날씨 데이터를 LSTM으로 처리하는 프로그램을 작성해보자. 사용하는 데이터 세는 Max Planck Institute for Biogeochemistry에서 기록한 Jena Climate 데이터 세트이다. 데이터 세트는 온도, 압력, 습도 등 14가지 특징으로 구성되며 10분에 한번씩 기록된다. https://keras.io./examples/timeseries/를 참조한다.
Keras documentation: Timeseries
keras.io.

















감사합니다.
공부한 내용을 복습/기록하기 위해 작성한 글이므로 내용에 오류가 있을 수 있습니다.
'인공지능' 카테고리의 다른 글
| [인공지능] YOLOv5를 이용한 전동 킥보드 사용자 탐지 (0) | 2022.09.23 |
|---|---|
| [인공지능] 딥러닝 express 연습문제 10장 (feat.CNN) (0) | 2022.09.23 |
| [인공지능] 딥러닝 express 연습문제 8장 (0) | 2022.09.22 |
| [인공지능] 심층 신경망(DNN) (1) | 2022.09.20 |
| [인공지능] 딥러닝 express 연습문제 7장 (0) | 2022.09.16 |