
티스토리 뷰
앞서 작성한 글들을 바탕으로 R을 이용해 여러 기본적인 통계를 실행합니다.
(수식에 대한 자세한 분석은 생략합니다. 이런 함수들이 있고 사용법을 익히는 정도 입니다!)
R은 다음과 같이 다양한 확률분포에 대해 여러 통계 함수들을 지원하고 있습니다.
| 확률분포 | 난수 발생 | 확률 밀도 함수 | 누적 분포 함수 | 분위수 |
| 이항분포 | rbinom | dbinom | pbinom | qbinom |
| F 분포 | rf | df | pf | qf |
| 기하분포 | rgeom | dgeom | pgeom | qgeom |
| 초기하분포 | rhyper | dhyper | phyper | qhyper |
| 음이항분포 | rnbinom | dnbinom | pnbinom | qnbinom |
| 정규분포 | rnorm | dnorm | pnorm | qnorm |
| 포아송 분포 | rpois | dpois | ppois | qpois |
| t 분포 | rt | dt | pt | qt |
| 연속 균등 분포 | runif | dunif | punif | qunif |

- fivenum( )
데이터를 최소값, 제1사분위수, 중앙값, 제3사분위수, 최대값으로 요약해준다.

- summary( )
fivenum함수와 유사하나 평균값까지 알려준다.
벡터요약 : 사분위수, 중앙값, 평균
행렬요약 : 열단위로 표시
요인요약 : 수준별 도수 표시
데이터프레임 요약 : 위 내용을 모두 포함

+ fivenum vs summary
이둘은 다른 식을 사용해 제1사분위수와 제3사분위수를 계산하기 때문에 결과에 차이가 있을수 있다. 실무에서는 summary를 주로 사용한다고 한다.
- quantile( 데이터, 백분율 )
백분위수를 구하기 위해 사용되는 함수이다.

- IQR( )
Inter-Quartile Range로 '제3사분위수 - 제1사분위수'를 구한다.

- table( )
각요소별 출연 횟수를 카운팅한다.
ex. 최빈값을 찾는 예제

- sample( 데이터, 표본크기, ... )
표본을 추출하기 위해서 사용한다. 매번 순서를 다르게 하기 때문에 데이터를 섞는 목적으로 주로 사용된다.
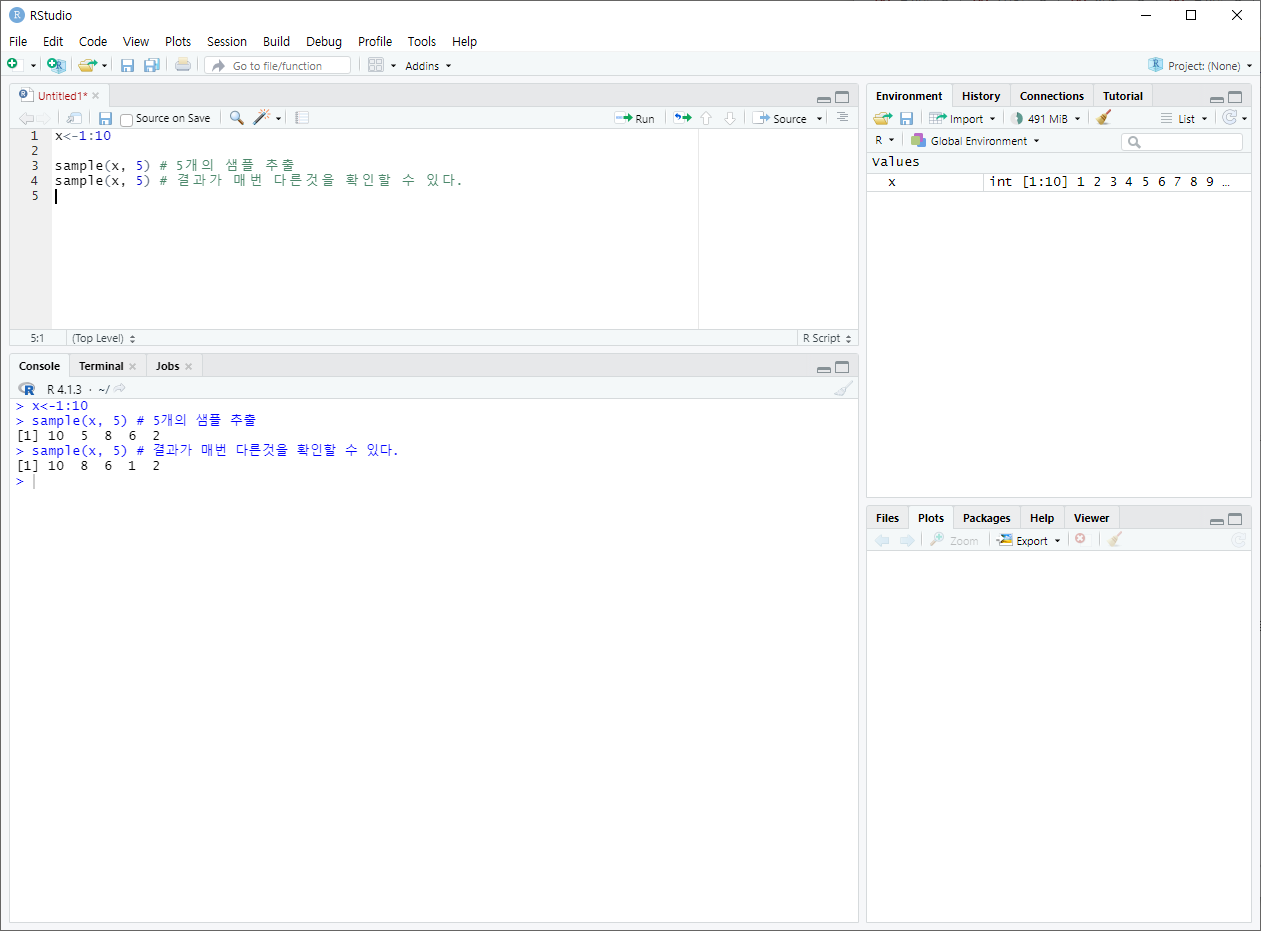
+ strata ( )
sampling라이브러리에 있으며, 층화 임의추출(모집단을 몇가지 특징을 기준으로 서브그룹으로 나누어, 각 그룹의 원소로부터 임의로 추출하는 법)을 위해 사용된다.
ex. R에 내장되어있는 iris데이터에서 단순 임의 추출(비복원)을 실행하는 예제. "Species"별로 1~3개의 데이터 추출.
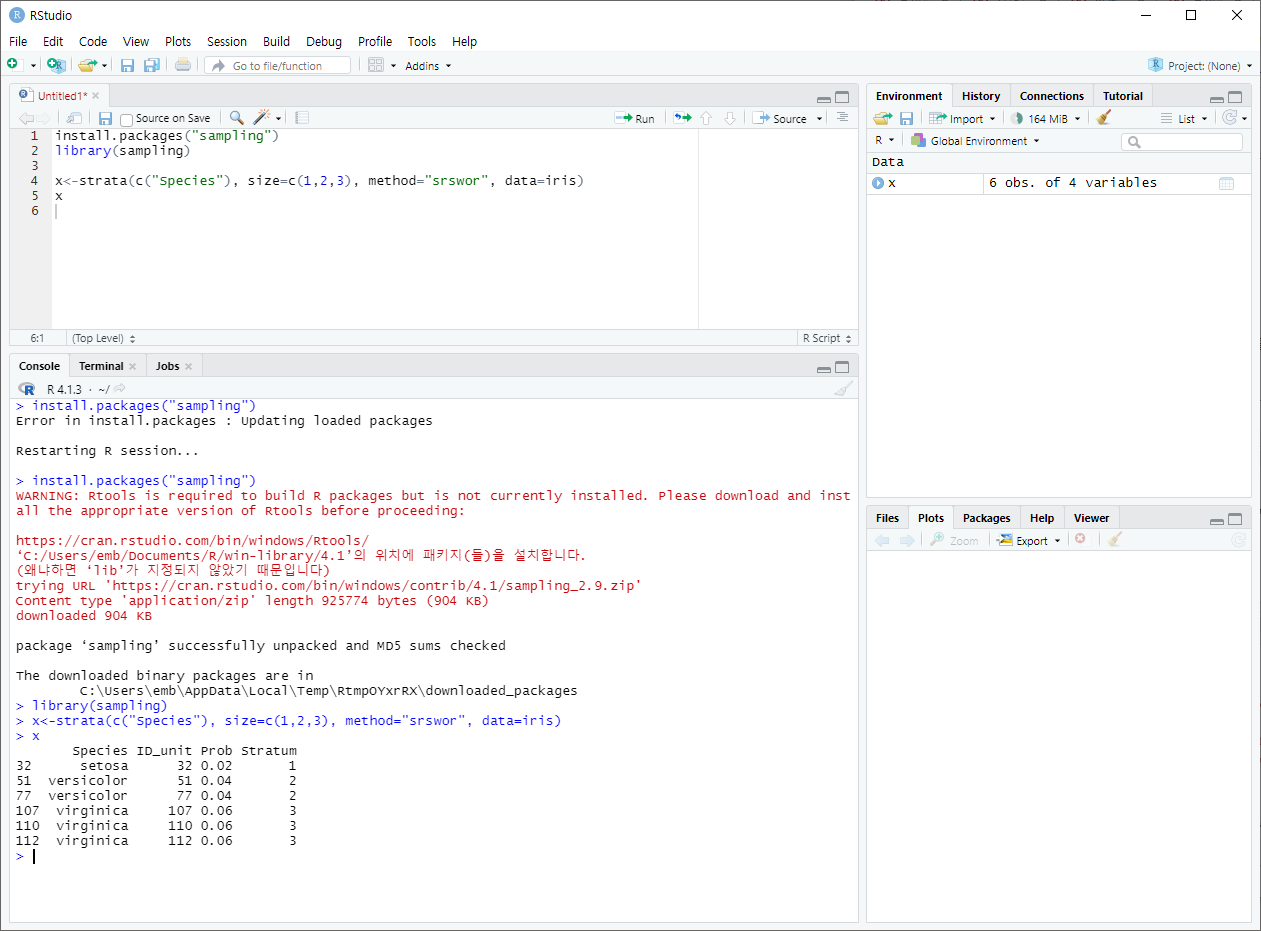
+결과로 반환된 행들의 데이터를 실제로 뽑아내고자 한다면 getdata( )를 사용해 데이터 프레임으로 변환한 뒤 추출한다.

- lapply ( )
summary와 같이 정보를 요약해 보여준다. 리스트를 요약할 때 일반적으로 사용한다.
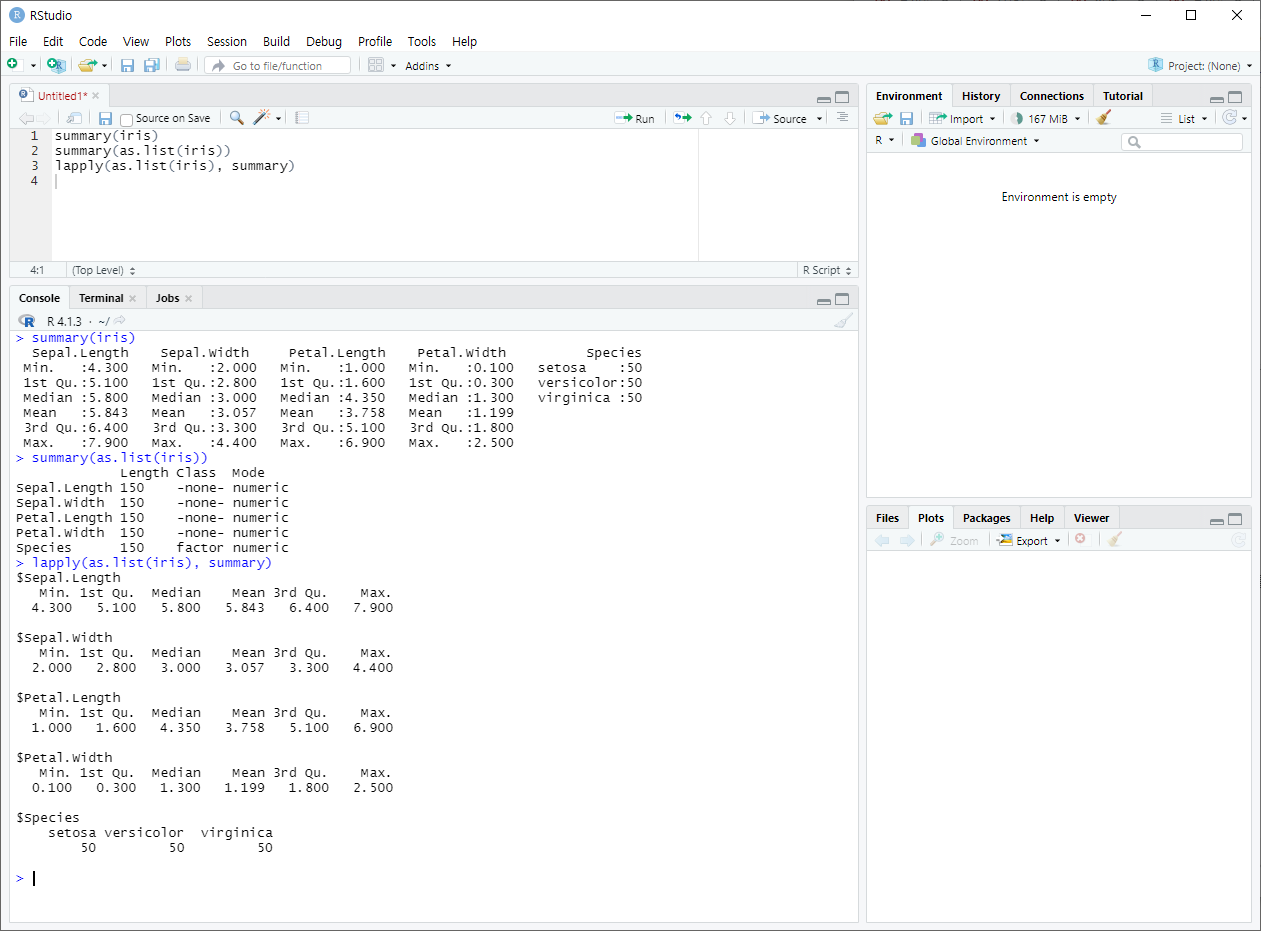
+ summary를 이용한 범주형 변수의 독립성 검정
두개의 범주형 변수가 있을때, 이들의 독립성을 검정하고 싶다면 카이제곱 검정(Chi-square test)를 사용한다.
ex. table 함수를 이용해 분할표를 생성한뒤 summary함수로 카이제곱 검정을 수행하는 예제.
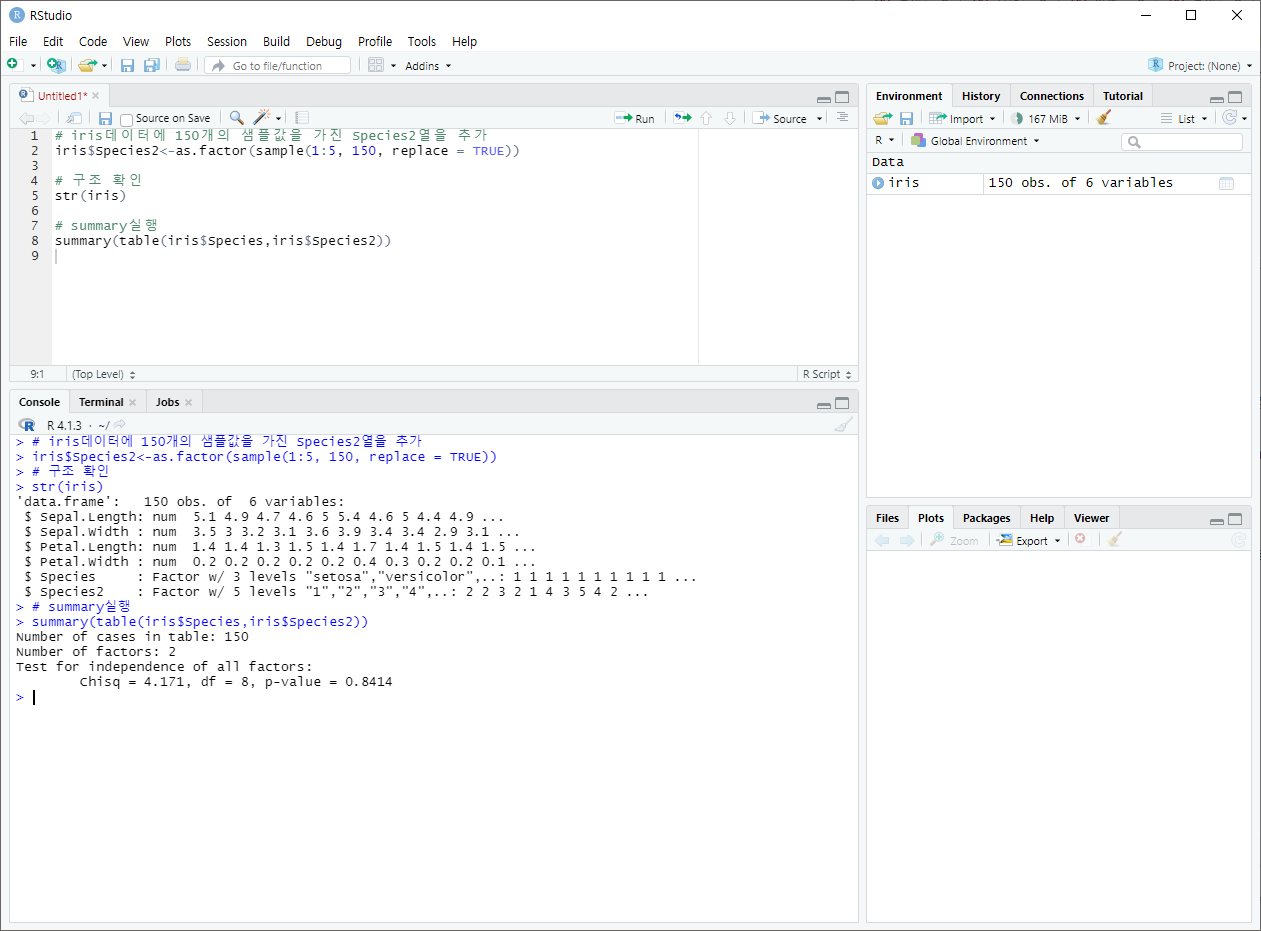
--> p-값이 0.05보다 크기 때문에 해당 변수들은 서로 독립적인 것을 알 수 있다.
- scale ( )
모든 원소에 대해 z점수를 계산한다. 벡터, 행렬, 데이터 프레임에서 사용가능하다.
+ center는 평균, scale는 표준편차이다.
- t.test( )
t 검정(모평균 검정)을 실행한다.
ex. 표본을 이용하여 모집단의 평균이 어떤 값을 가지고 있는지 확인하는 예제. 평균이 95, 표준편차가 10인 모집단에서 표본을 추출했을 때 평균이 90일 수 있는지 알아본다.

--> p-값이 0.05보다 작기 때문에 평균이 90이라는 가설은 기각한다.
+ conf.level
출력에 다른 신뢰구간을 확인하고 싶다면 이 인자의 값을 설정하면 된다.
ex. 신뢰수준 99% 예제

- prop.test( )
모비율 검정, 표본 비율을 이용하여 모집단 비율을 구할때 사용한다.
ex. 100 경기 중 56번 이겼을 때, 앞으로의 경기에서 절반 이상을 이길 수 있을것인가? (귀무가설 P≤0.5) 라는 가설을 검증하는 예제

--> p-값이 0.05보다 큼으로 귀무가설을 기각할 수 없다.
- shaprio.test( )
정규성 검정을 위해 사용. 표본이 정규 분포로 된 모집단에서 나온것인지 아닌지를 검정할 때 이용된다.
+ Anderson-Darling 검정, Cramer-von Mises 검정, 피어슨 카이제곱 검정 등이 포함되어있는 nortest 패키지에 포함 되어있다.

--> p-값이 0.05보다 작기 때문에 정규 모집단으로 부터 추출되었다고 보기 어려움
- cor.test( )
변수 사이의 상관관계가 통계적으로 유의한지 확인하기 위해 사용

--> p-값이 0.05보다 작기 때문에 귀무가설을 기각. 유의하지 않다.
[참고자료]
CRAN: Manuals
The R Manuals edited by the R Development Core Team. The following manuals for R were created on Debian Linux and may differ from the manuals for Mac or Windows on platform-specific pages, but most parts will be identical for all platforms. The correct ver
cran.r-project.org
감사합니다.
2022년 AI분석을 위한 R통계교육의 수업내용을 정리한 글입니다.
공부한 내용을 복습/기록하기 위해 작성한 글이므로 내용에 오류가 있을 수 있습니다.
'R' 카테고리의 다른 글
| [R] 데이터 시각화 - 그래프 활용과 Plot (0) | 2022.06.30 |
|---|---|
| [R] 고급 통계 (0) | 2022.06.30 |
| [R] 모드(mode)와 자료구조 (0) | 2022.06.28 |
| [R] 변수와 벡터 (0) | 2022.06.28 |
| [R] 통계의 이해 (0) | 2022.06.15 |