
티스토리 뷰
Keras의 Sequential 모델을 사용해 MNIST 숫자를 학습시키고 테스트합니다.
Google의 Colab 환경에서 실행합니다.
Google Colaboratory
colab.research.google.com
Sequential 모델
Sequential 모델은 피드포워드 신경망(입력신호가 한방향으로 전달되는 신경망) 을 구현하는 가장 기초적인 모델입니다. 지원하는 여러 메소드들을 이용해 신경망을 구현하고 학습시킬 수 있습니다.
Keras documentation: The Sequential model
» Developer guides / The Sequential model The Sequential model Author: fchollet Date created: 2020/04/12 Last modified: 2020/04/12 Description: Complete guide to the Sequential model. View in Colab • GitHub source Setup import tensorflow as tf from tens
keras.io
MNIST
MNIST(Modified National Institute of Standards and Technology)는 손으로 쓴 숫자들로 이루어진 대형 데이터셋 입니다. 기계 학습 분야의 트레이닝 및 테스트에 널리 사용되고 있습니다.

모델 학습
그럼 Colab에서 Sequential 모델을 사용해 MNIST 데이터 셋을 학습시켜 보겠습니다.
import matplotlib.pyplot as plt
import tensorflow as tf
# 훈련, 테스트 데이터 셋 가져오기
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
# 데이터 확인
# print(train_images.shape)
# print(train_labels)
# print(test_images.shape)
# plt.imshow(train_images[0], cmap="Greys")
# 모델 생성
model = tf.keras.models.Sequential()
# 레이어 추가
model.add(tf.keras.layers.Dense(512, activation='relu', input_shape=(784,))) # 렐루
model.add(tf.keras.layers.Dense(10, activation='sigmoid')) # 시그모이드
# 컴파일
model.compile(optimizer='rmsprop', # 손실함수 기반의 신경망 파라미터 최적화 알고리즘
loss='mse', # 손실함수 : 평균 제곱 오차
metrics=['accuracy']) # 지표 : 정확도
# 이미지 평탄화
train_images = train_images.reshape((60000, 784))
train_images = train_images.astype('float32') / 255.0
test_images = test_images.reshape((10000, 784))
test_images = test_images.astype('float32') / 255.0
# 원핫 엔코딩
train_labels = tf.keras.utils.to_categorical(train_labels)
test_labels = tf.keras.utils.to_categorical(test_labels)
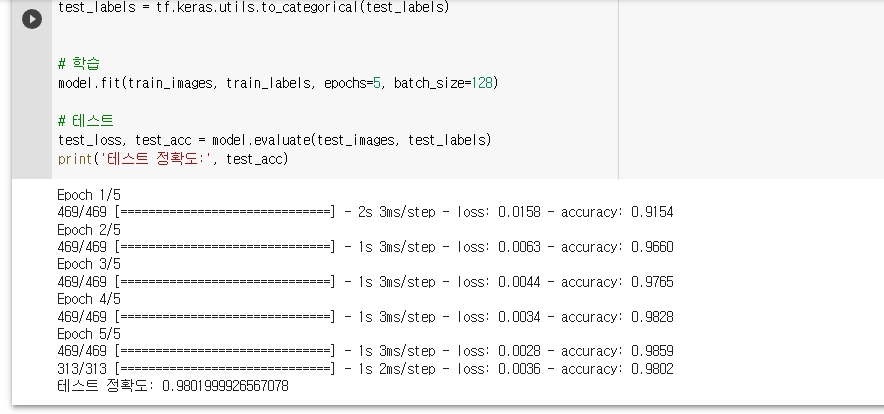
# 학습
model.fit(train_images, train_labels, epochs=5, batch_size=128)
# 테스트
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('테스트 정확도:', test_acc)
학습결과 테스트 데이터에 대해 약 98%의 정확률이 나온것을 확인할 수 있습니다.
모델을 실제 데이터에 적용해 보고 얼마나 잘 분류하는지 확인해 보겠습니다. 저는 그림판을 켜 아래와 같이 숫자 '4' 를 적고 test.png 파일로 저장하였습니다.

파일을 열어 colab상에 파일을 업로드 한 뒤 아래 코드를 실행 시킵니다. (파일명을 다르게 하셨다면 코드를 수정하시면 됩니다.)
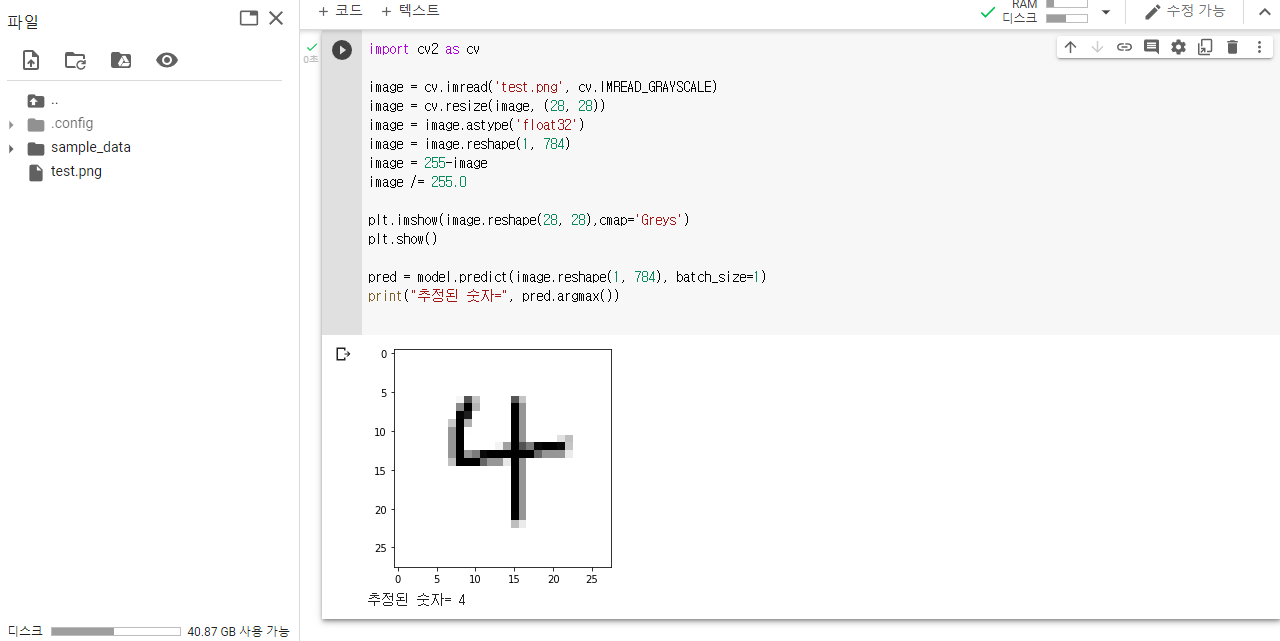
import cv2 as cv
# 이미지 읽기
image = cv.imread('test.png', cv.IMREAD_GRAYSCALE)
# 데이터 전처리
image = cv.resize(image, (28, 28))
image = image.astype('float32')
image = image.reshape(1, 784)
image = 255-image
image /= 255.0
# 이미지 출력 (확인용)
plt.imshow(image.reshape(28, 28),cmap='Greys')
plt.show()
# 모델 사용
pred = model.predict(image.reshape(1, 784), batch_size=1)
print("추정된 숫자=", pred.argmax())
실행 결과 입니다. 모델이 숫자을 잘 분류한것을 확인할 수 있습니다.
'인공지능' 카테고리의 다른 글
| [인공지능] 심층 신경망(DNN) (1) | 2022.09.20 |
|---|---|
| [인공지능] 딥러닝 express 연습문제 7장 (0) | 2022.09.16 |
| [인공지능] 딥러닝 express 연습문제 6장 (0) | 2022.09.14 |
| [인공지능] Numpy로 역방향전파 구현하기 (1) | 2022.09.14 |
| [인공지능] 딥러닝 express 연습문제 4장 (1) | 2022.09.08 |